Google announced Google App Engine, their long-awaited answer to web services offered by Amazon and others. Google took a different approach to their competitors by including a full application stack for developers. This made App Engine less flexible, by forcing developers to use the programming tools and libraries that Google supplied, but it did have the advantage that you could get your web app up and running very quickly, and easily leverage Google’s infrastructure. An app could scale up with very little work on the part of the developer — in theory.
Although the theory was sound, in practice, developers were quite limited in the resources they had available, and there was no option to increase those resources. Google has now addressed that, allowing developers to pay for resources at rates comparable to Amazon Web Services, so it seems App Engine may finally be ready for prime time.
A couple of months ago, my interest in App Engine was piqued enough to take a closer look. I spent about a week developing a Twitter-like web site called Mental Drain. (The site is fully operational, if a bit rough around the edges. You can try it out by logging in with your Google account.) In the rest of this post, I’ll discuss what’s involved in developing a web app with App Engine, and provide a few examples from the code I wrote for Mental Drain.
Table of Contents
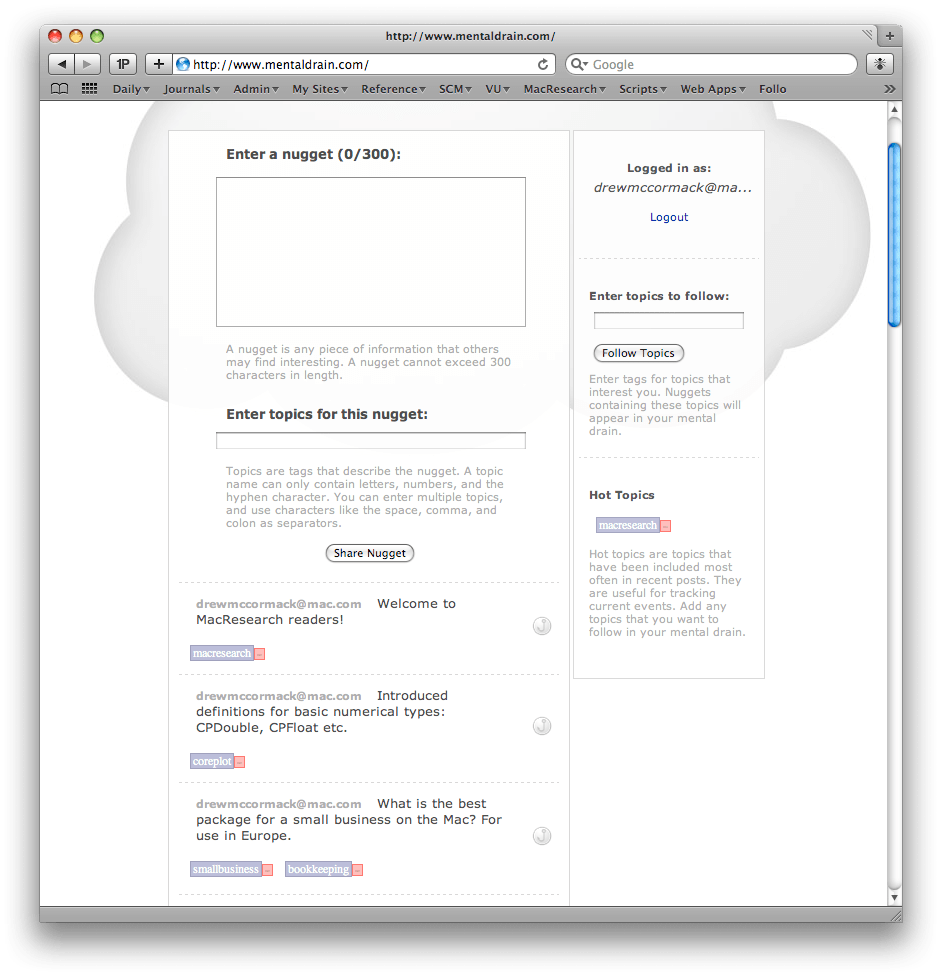
Mental Drain For Mac
Before we delve into App Engine, it is worth briefly considering the app that I will reference throughout this post: Mental Drain. As mentioned earlier, Mental Drain is based on Twitter, but with a few twists: When using Twitter, you generally follow people you know or admire, and receive all of the messages that they post. With Mental Drain, you receive posts on the topics that interest you, regardless of who posted them. In other words, you subscribe to topics (tags), rather than people. It’s like belonging to many different ad hoc communities, and getting all the messages in a single stream — your mental drain.
What is a Web Application?
Some of you reading this may still be wondering what App Engine actually does. If you don’t have any experience developing for the web, you probably don’t know the difference between a web application and an ‘ordinary’ web site. To get everyone on the same page, a web application is a web site which is interactive, and backed by some sort of database. The web site is dynamically updated based on the data in the store. Nearly every web site you come across these days is in fact a web application, from iTunes to Twitter and Amazon.
What is App Engine?
Google App Engine allows you to develop web applications backed by the mother of all data stores: Big Table. Big Table is Google’s secret sauce, a super-fast, super-scalable store that contains all of the data that makes Google’s search and other services what they are. App Engine opens that power up to outside developers.
App Engine provides a whole range of facilities and frameworks, all based around the scripting language Python. Much of App Engine is based on a web development framework called Django; even where Google have developed their own proprietary code — such as the all-important Datastore API — they seem to have been inspired by Django.
Signing Up and Installing
Signing up as a developer for App Engine is very easy, and free. You simply visit the App Engine site, and use your Google login to create an account. This allows you to write up to 10 applications; free apps are quite restricted in their resource quotas, but for many small sites, they are perfectly adequate. If your site takes off, you will have to decide whether to pay for extra resources, but that is quite a luxurious position to be in.
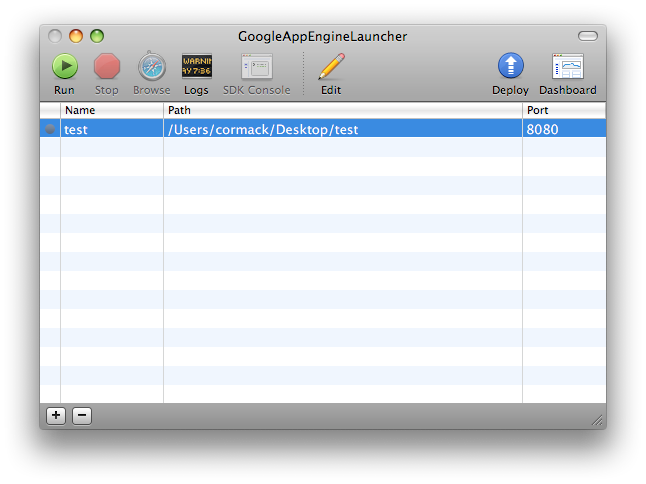
Installing Google App Engine on your local development machine is also very easy. Google provide native installers for Windows, Mac, and Linux. On the Mac, you simply open the downloaded disk image, and drag the GoogleAppEngineLauncher application to your hard disk. When you launch the app, it will offer to create some symbolic links to make command line usage easier. That’s really all there is to it.
Setting Up a Project
We won’t go into great depth as to how you setup a project. Google provide quite a good introductory tutorial, which is probably the best place to start.
The process is quite straightforward: You create a directory for your project, and you add a configuration file to it called ‘app.yaml’, in the YAML format. Here is the Mental Drain configuration, by way of example.
application: mental-drain
version: 1
runtime: python
api_version: 1
handlers:
- url: /stylesheets
static_dir: stylesheets
- url: /images
static_dir: images
- url: /data
static_dir: data
- url: /scripts
static_dir: scripts
- url: /.*
script: mentaldrain.py
The app.yaml file describes the app’s structure, including its version number and runtime environment. It also tells App Engine how to handle requests for URLs. For example, the Mental Drain project has subdirectories for static content like images, stylesheets, and scripts. As you can see, the app.yaml file maps URLs matching certain patterns to these directories. Any URL that begins with /images will be treated as a request for static data, and will be resolved to the images subdirectory. (Note that although the URL and directory names are the same in this example, that is not a requirement.) Anything not matching these particular cases is matched by the last entry, which includes a wild card, and is resolved to the main application script: mentaldrain.py.
Controllers
App Engine, like nearly all modern web development environments, is based on the Model-View-Controller (MVC) paradigm. The model is the data in the data store, the view is what appears in the user’s browser, and the controller is the code that binds the two together.
The controller code for Mental Drain, which receives requests and decides what to do with them, is mostly concentrated in a single file: mentaldrain.py. We saw that most requests are directed to this script due to the configuration in app.yaml. A controller script usually begins by importing a bunch of useful App Engine modules.
from google.appengine.api import users
from google.appengine.ext import webapp, db
from google.appengine.ext.webapp.util import run_wsgi_app, login_required
from google.appengine.ext.webapp import template
from google.appengine.api import memcache
The modules you need in your app will vary, but the ones listed above are quite common. We’ll see them in use as we go.
Somewhere in the controller file, usually toward the bottom, a WSGIApplication object will be created, and initialized.
application = webapp.WSGIApplication(
[('/postnugget', NuggetFactory),
('/addteachertopics', TopicHandler),
('/updateteachertopic', TopicHandler),
('/fishout', FeedbackHandler),
('/', MainPage)],
debug=True)
def main():
run_wsgi_app(application)
if __name__ == "__main__":
main()
The application object maps URLs to particular handler classes, which are usually defined in the same controller file. In the example above, if a URL begins with /postnugget, it will be handled by the NuggetFactory class. Note that a single class can handle multiple types of URLs, as is the case for TopicHandler.
The handler classes themselves must be subclasses of webapp.RequestHandler. They can handle both HTTP get and post requests, simply by implementing the get and post methods, respectively.
For example, the TopicHandler class handles post requests for a user to subscribe to one or more topics (tags) in a string, or a get request to add or remove a particular topic from a user’s follow list.
class TopicHandler(webapp.RequestHandler):
def post(self):
nugget = None
if users.get_current_user():
teacher = Teacher.teacher(users.get_current_user())
tags = ParseTags(self.request.get('topics'))
topics = [Topic.topic(tag).key() for tag in tags]
for t in topics:
TeacherTopic.teacherTopic(teacher, t)
self.redirect('/')
@login_required
def get(self):
teacher = Teacher.teacher(users.get_current_user())
tags = ParseTags(self.request.get('topic'))
action = self.request.get('action')
if len(tags) == 1:
topic = Topic.topic(tags[0])
if action == 'add':
TeacherTopic.teacherTopic(teacher, topic)
elif action == 'remove':
tt = TeacherTopic.teacherTopic(teacher, topic)
if tt: tt.delete()
Getting the parameters passed with the request is trivial using the request dictionary. The string passed in the topics argument is retrieved like this
self.request.get('topics')
App Engine supplies many different APIs: in the code above, you can see examples of retrieving the current user
users.get_current_user()
and redirecting the browser to a different URL
self.redirect('/')
Another very common aspect of handling requests in a controller is returning HTML from the request, to be displayed in the user’s browser. This amounts to writing data to the request output stream, as in the following piece of code from Mental Drain
def showInfo(self):
url = users.create_login_url(self.request.uri)
templateValues = {'url': url}
path = os.path.join(os.path.dirname(__file__), 'templates', 'index.html')
self.response.out.write(template.render(path, templateValues))
Although you can simply write out HTML strings directly, it is more common to separate the HTML from the controller code in template files. This snippet shows how a template is located in the ‘templates’ subdirectory, and then instantiated with a particular URL argument. The resulting string is written to self.response.out, the request’s output stream, which results in it appearing in the user’s browser.
Views
We already started to consider the View of MVC in the controller section above. The View is what appears in the user’s browser, and is usually generated by App Engine using HTML template files. The template engine in App Engine is from the Django framework. Here is a relatively simple template for the info page of Mental Drain.
{% extends "base.html" %}
{% block content %}
<h1 class="title">Mental Drain</h1>
<h3>What?</h3>
<p>Mental Drain is a service for creating ad hoc online communities in the blink of an eye.
Creating a new community is as simple as entering a topic — 'news', 'fast-cars',
'french-history', 'spanish', 'ucla-comp-sci' — anyone can create a community,
and anyone can join an existing community.</p>
<h3>Not Who ... What</h3>
<p>You can follow as many topics — join as many communities — as you please.
You receive messages that are posted on any topic you are following. In contrast to other
messaging services, the focus of Mental Drain is not on who is posting a message, but what
the message contains. You don't follow people, you follow topics.</p>
<h3>Your Mental Drain</h3>
<p>Each user has their own 'mental drain'. Your mental drain is the stream of messages
that have been posted on any of the topics that you are following. It's similar to an
email Inbox or RSS feed.</p>
<h3>Fishing for Nuggets</h3>
<p>A message posted to Mental Drain is called a 'nugget'. Mental Drain is more than just
a means of communicating — it's also a learning tool. Any nugget can be 'fished out'
of your mental drain. When a nugget gets fished out, it is scheduled to reappear every so
often in your mental drain. This can be useful for remembering interesting nuggets.</p>
<h3>Mental Drain v. Mental Case</h3>
<p>Mental Drain is loosely-based on <a href="http://www.macflashcards.com">Mental Case</a>,
an application for the Mac and iPhone. Mental Case has advanced features for organizing and
studying information; Mental Drain is much simpler, and focussed on social learning.</p>
{% endblock %}
{% block sidebar %}
<div class="lastsidebarsection">
<p>You are not logged in.</p>
<p><a href="{{ url }}">Login</a></p>
<p class="help">You can login with a Google account.</p>
</div>
{% endblock %}
It looks a lot like ordinary HTML, but has embedded directives and variables. The code {{ url }}, for example, will be substituted with the string supplied for the url variable when instantiating the template. The template engine can also handle many other operations common to programming, such as conditional branching and looping.
Django templates can be arranged into an inheritance hierarchy much like in Object-Oriented Programming (OOP) languages. The page above extends the file base.html, which includes repetitive code such as the head section, with links to CSS and Javascript files.
Two blocks have been defined, for the main content, and the sidebar content. These override blocks defined in base.html. Put simply, the blocks replace the blocks of the same name from the base.html file in the generated output. Here is the base.html file:
<html>
<head>
<link type="text/css" rel="stylesheet" href="/stylesheets/main.css" />
{% block extrahead %}
{% endblock %}
</head>
<body>
<div id="container">
<img src="/images/Cloud.jpg" id="cloud" />
<div id="content">
{% block content %}
{% endblock %}
</div>
<div id="sidebar">
{% block sidebar %}
{% endblock %}
</div>
</div>
</body>
</html>
Even if you aren’t using App Engine, a template engine like Django’s provides a powerful way to avoid repetitive coding, keep program logic and presentation code separate, and structure a web site much more cleanly.
Models
The model layer is about how data is stored in Big Table. Google doesn’t give you direct access to Big Table; you get indirect access through the Datastore API.
The Datastore API is similar to Core Data framework on the Mac, in that you define entities and relationships between those entities. When you use Core Data, you do this with a graphical tool; for App Engine, you define Python classes and add entity properties as class members. For example, the Nugget entity in Mental Drain, which represents a single post, begins like this
class Nugget(db.Model):
teacher = db.ReferenceProperty(Teacher, collection_name='nuggets')
created = db.DateTimeProperty(auto_now_add=True)
content = db.TextProperty(required=True)
Entity classes generally derive from the db.Model class, and contain class members for each property. The created property, for example, is a date, so it is assigned to a DateTimeProperty object. content is the textual content of the post, so this is a TextProperty. There are many other property types available, including generic data blobs, which can be used for storing images and files.
The teacher property is somewhat different, in that it defines a relationship to another entity: Teacher. A teacher in Mental Drain is just a user — we are all teachers in ‘the drain’ — and this property maps a particular post (nugget) back to the user that posted it. A ReferenceProperty is used to create such a relationship.
Relationships can of course take many forms: one-to-one, one-to-many, many-to-many. The relationship of a nugget to its teacher is actually many-to-one, because a teacher can post many nuggets, so where is the ‘many’ side of the relationship?
In Core Data, this would be made explicit by adding an inverse property, nuggets, to the Teacher entity, but in App Engine, nothing is added to Teacher at all. Instead, an implicit property is created behind-the-scenes called nuggets; this property is not a list or array of nuggets, as you might expect, but a query that can be used to retrieve all of the nuggets that belong to the teacher from the data store.
Although all of this works fine once you get used to it, I think I prefer having an explicit property added to the Teacher class — it certainly makes reading the code simpler.
Fetching and Saving Data
We mentioned you can use queries to retrieve objects from the store. This is analogous to using ‘fetch requests’ in Core Data, or an SQL query for a relational database. App Engine even supports an SQL like query language called GQL, but for many queries, you can use a simplified syntax. For example, here is how Mental Drain checks if a particular user already exists in the store
teacher = Teacher.all().filter('user =', user).get()
if teacher:
# Teacher exists already
...
else:
# Create a new teacher
...
The all class method returns a query for all Teacher instances in the data store. This is then modified by the filter method to only look for those Teachers where the user property is equal to a particular user. Finally, the get method returns the user, if there is one, and None otherwise. (If you are looking for more than one object, you use the fetch method instead of get.)
Whenever you create a new object, you need to make sure it is saved. The put method ensures that the data is persisted in the data store.
newTeacher = Teacher(user=user)
newTeacher.put()
Testing
Google have gone to quite a lot of trouble to make working with App Engine a pleasure. You can test your app on your local machine with a test store before uploading it to the Google servers. You can even login with different fictional user names to test your app for multiple users. You can start the test server using the GoogleAppEngineLauncher app, or on the command line:
dev_appserver.py <path_to_app_directory>
Your app will then be available at the address http://localhost:8080.
Deploying an App
Once an app is ready for prime time, it is just as easy to deploy it as it is to test. Again, you can use GoogleAppEngineLauncher to upload the app, or you can use the command line:
appcfg.py update <path_to_app_directory>
Gotchas
There are a few gotchas to be aware of. For one, you have no direct access to your app’s data. If you want to perform a migration, or other manipulation of that data, you will need to do so by writing application code, and running that via URL requests.
To complicate matters somewhat, Google have placed a limit on the number of items you can retrieve from the store with one query, and that is currently set at 1000. If you have a million items in the store, you need to develop a script to iterate through those items 1000 at a time.
Finally, you have to be aware that there are limits on how long a single request can run, so if your data transformation takes a considerable amount of time, you will have to break it up into a chain of contiguous URL requests. The App Engine documentation explains how you best can do this.
Advanced Stuff
This has been a very high-level look at App Engine. The objective was to give you an idea of the scope of the project, some of its advantages, and some of its disadvantages. We haven’t touched on anything particularly advanced, but that doesn’t mean it can’t be done. For example, Mental Drain uses Ajax techniques for updating data without reloading the page, and the Memcache API to improve performance.
Stay connected